Introduction
In France in 2020, there were approximately 4 and 5 million deaf or
hard of hearing people who have difficulties or are simply unable to
communicate through speech. Concerning the deaf speakers of French
Sign Language (LSF), the figures are uncertain: they oscillate between
80,000 and 120,000, depending on the sources.
This sign language is too little used because it requires a significant
investment to learn it and most people do not use it directly in their
lives.
hard of hearing people who have difficulties or are simply unable to
communicate through speech. Concerning the deaf speakers of French
Sign Language (LSF), the figures are uncertain: they oscillate between
80,000 and 120,000, depending on the sources.
This sign language is too little used because it requires a significant
investment to learn it and most people do not use it directly in their
lives.
Publicly available datasets are limited in both quantity and quality,
making many traditional machine learning algorithms inadequate for the
task of building classifiers. Language recognition (SLR) methods typically
extract features via deep neural networks and suffer from overlearning
due to their imprecise and limited data. Many of these models are based
directly on the analysis of retrieved images and the analysis of image
pixels.
Many early SLR systems used gloves for data retrieval and accelerometers
to acquire hand features.
While these techniques offered the advantage of accurate positions,
they did not allow for full natural movement and restricted mobility,
altering the signs performed. Further trials with a modified glovelike
device, which was less restrictive, attempted to address this issue
But recently, skeleton coordinate-based action recognition has been
attracting more and more attention because of its invariance to subject or
background, whereas skeleton coordinate-based SLR only takes the data
that is important for its learning.
This report deals with the implementation of an AI for sign language
recognition (SLR) using the mediapipe framework in order to extract
the user’s coordinates and to analyze them through a model in
pytorch.
making many traditional machine learning algorithms inadequate for the
task of building classifiers. Language recognition (SLR) methods typically
extract features via deep neural networks and suffer from overlearning
due to their imprecise and limited data. Many of these models are based
directly on the analysis of retrieved images and the analysis of image
pixels.
Many early SLR systems used gloves for data retrieval and accelerometers
to acquire hand features.
While these techniques offered the advantage of accurate positions,
they did not allow for full natural movement and restricted mobility,
altering the signs performed. Further trials with a modified glovelike
device, which was less restrictive, attempted to address this issue
But recently, skeleton coordinate-based action recognition has been
attracting more and more attention because of its invariance to subject or
background, whereas skeleton coordinate-based SLR only takes the data
that is important for its learning.
This report deals with the implementation of an AI for sign language
recognition (SLR) using the mediapipe framework in order to extract
the user’s coordinates and to analyze them through a model in
pytorch.
Project details
At the time of the program's launching, the user sees a he sees a short video of a person, which makes him a demonstration of a word in sign language. He must then repeat this movement by having
a return on the camera of the device. He can see in real time the points
detected on his body. When he has validated the movement, a second
tutorial appears about another movement and he must do it again, and
so on... This project does not use motion capture gloves like most SLR
projects, which required expensive and restrictive equipment. The user’s
coordinates are retrieved directly with an AI and projected in 2D. This
seems to be the most efficient solution today. [dreuw2007speech]
All the environment is implemented in Python and the part related with
the display has to be implemented in JS on the augmented mirror.
At the time of the program's launching, the user sees a he sees a short video of a person, which makes him a demonstration of a word in sign language. He must then repeat this movement by having
a return on the camera of the device. He can see in real time the points
detected on his body. When he has validated the movement, a second
tutorial appears about another movement and he must do it again, and
so on... This project does not use motion capture gloves like most SLR
projects, which required expensive and restrictive equipment. The user’s
coordinates are retrieved directly with an AI and projected in 2D. This
seems to be the most efficient solution today. [dreuw2007speech]
All the environment is implemented in Python and the part related with
the display has to be implemented in JS on the augmented mirror.
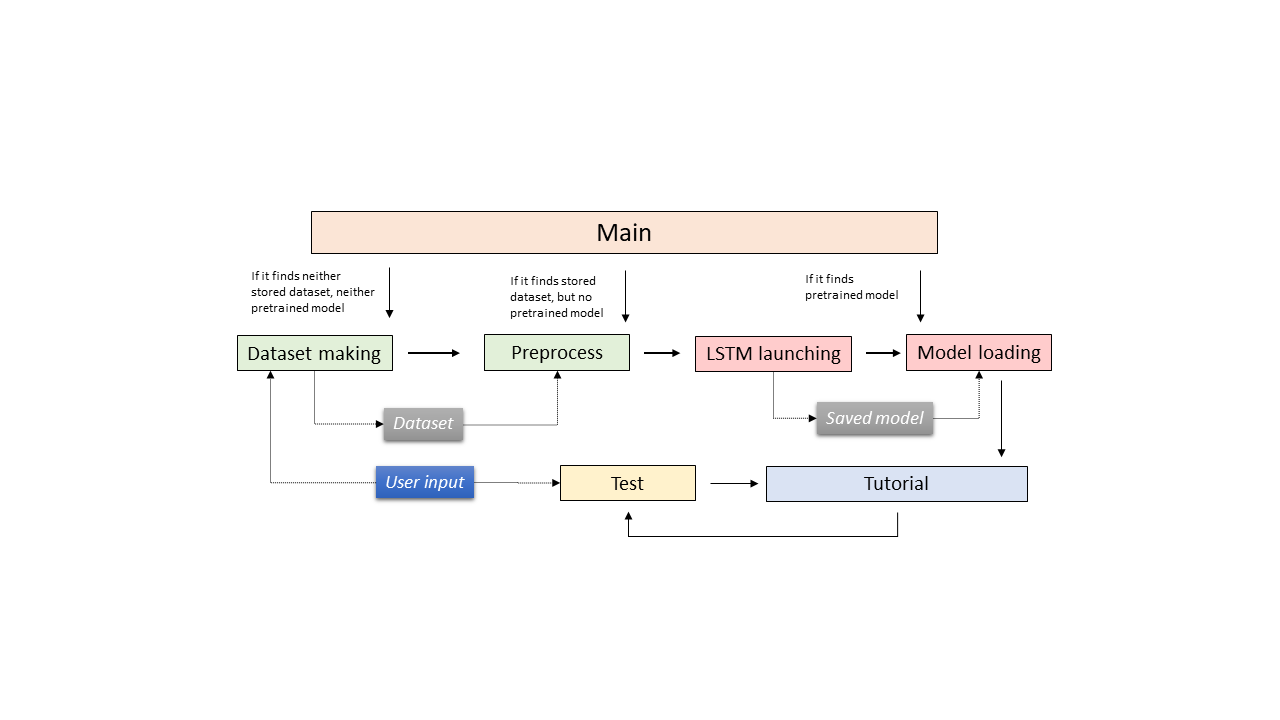
Project structure
The project is divided into 8 different modules: a main one that initializes
the parameters and launches the different processes, an optional phase of
dataset creation, a tutorial phase that displays the skeleton for the tutorial,
a preprocess phase that retrieves the data from the dataset and formats
them, a data augmentation module, a model calculation or retrieval of
the saved weights, and a user test phase that tries to redo the movement.
IA model
The AI for sign language recognition (SLR) is designed to make the creation easier, facilitating the creation of the dataset, implementing new models, visualization of training results, as well as a dynamic visualisation of recorded movements. The model is composed of a bidirectional LTSM, a linear, a dropout, a batchnorm1d, a relu, and an other Linear. The AI trained on 16 different signs or 1600 sequences. I reach an accuracy of 87% on the test set and 96% on the training.